1.5. 感知机¶
感知机是最简单的线性二分类模型,如果要处理的数据是线性可分的,则该模型能取得很好的效果,如果数据不是线性可分的,则该模型不能取得很好的效果。以二维平面为例,如果要分类的点,能被一条直线分开,直线的一侧是正类,直线的另一侧是负类,则说明数据是线性可分的。如果数据需要一个圆来分开则说明数据不是线性可分的,曾经感知机因为不能处理异或问题,而被人批判,导致神经网络的研究停滞了几十年。 深度学习模型的典型例子是前馈深度网络或多层感知机(multilayerperceptron, MLP)。多层感知机仅仅是一个将一组输入值映射到输出值的数学函数。该函数由许多较简单的函数复合而成。我们可以认为不同数学函数的每一次应用都为输入提供了新的表示。
1.5.1. 单层感知机¶
人造神经元是所有神经网络的核心。它由两个主要部分构成:一个加法器,将所有输入加权求和到神经元上;一个处理单元,根据预定义函数产生一个输出,这个函数被称为激活函数。每个神经元都有自己的一组权重和阈值(偏置),它通过不同的学习算法学习这些权重和阈值:
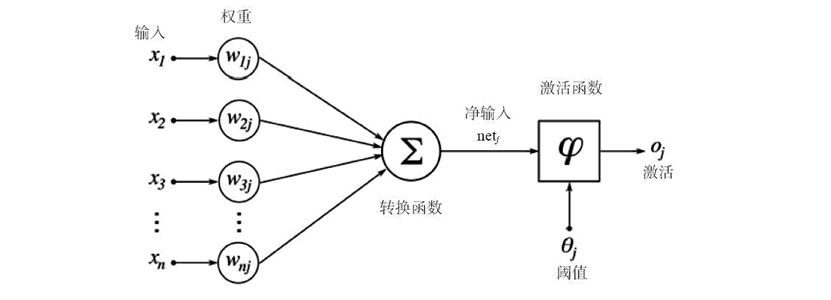
当只有一层这样的神经元存在时,它被称为感知机。输入层被称为第零层,因为它只是缓冲输入。存在的唯一一层神经元形成输出层。输出层的每个神经元都有自己的权重和阈值。
当感知机使用阈值激活函数时,不能使用 TensorFlow 优化器来更新权重。我们将不得不使用权重更新规则:
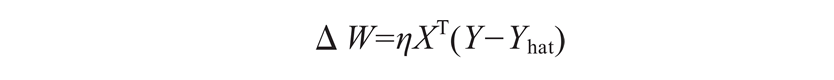
η 是学习率。为了简化编程,当输入固定为 +1 时,偏置可以作为一个额外的权重。那么,上面的公式可以用来同时更新权重和偏置。
def perceptron():
"""
当只有一层这样的神经元存在时,它被称为感知机
:return:
"""
learn_rate = 0.4
epsilon = 1e-03
max_epochs = 1000
T, F = 1., 0.
X_in = [[T, T, T, T], [T, T, F, T], [T, F, T, T], [T, F, F, T],
[F, T, T, T], [F, T, F, T], [F, F, T, T], [F, F, F, T]]
Y = [[T], [T], [F], [F], [T], [F], [F], [F]]
W = tf.Variable(tf.random_normal(shape=(4, 1), stddev=2))
h = tf.matmul(X_in, W)
# Y_hat = threhold(h)
Y_hat = tf.sigmoid(h)
error = Y - Y_hat
mean_error = tf.reduce_mean(tf.square(error))
dW = learn_rate * tf.matmul(X_in, error, transpose_a=True)
# 更新权重
train = tf.assign(W, W + dW)
init = tf.global_variables_initializer()
epoch = 0
err = 1
with tf.Session() as sess:
sess.run(init)
opoches, errs, = [], []
while err > epsilon and epoch < max_epochs:
epoch += 1
_, err = sess.run([train, mean_error])
logger.info("epoch {0} mean error {1}".format(epoch, err))
opoches.append(epoch)
errs.append(err)
plt.title("perceptron epoch loss")
plt.xlabel("opoch")
plt.ylabel("error")
plt.plot(opoches, errs)
plt.show()
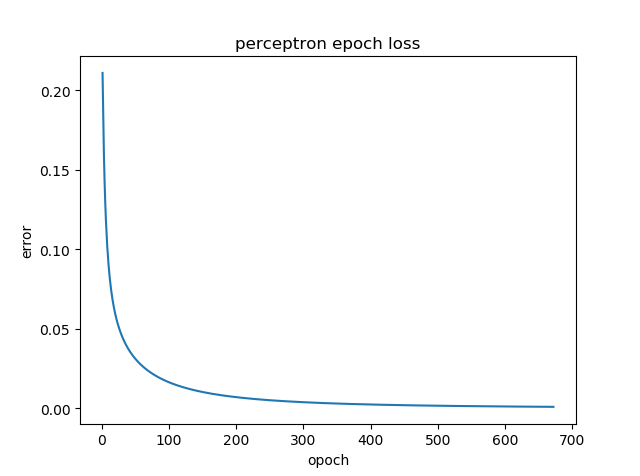
输出结果图:
1.5.2. 多层感知机¶
当存在许多这样的层时,网络被称为多层感知机(MLP)。MLP有一个或多个隐藏层。这些隐藏层具有不同数量的隐藏神经元。每个隐藏层的神经元具有相同的激活函数:
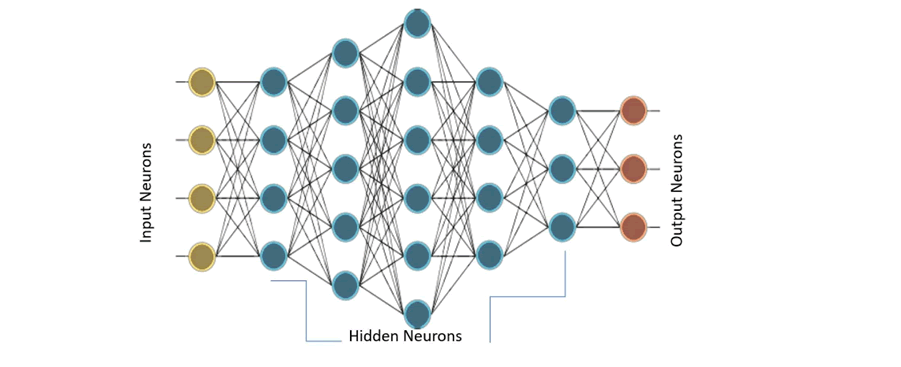
上图的 MLP 具有一个有 4 个输入的输入层,5 个分别有 4、5、6、4 和 3 个神经元的隐藏层,以及一个有 3 个神经元的输出层。在该 MLP 中,下层的所有神经元都连接到其相邻的上层的所有神经元。因此,MLP 也被称为全连接层。MLP 中的信息流通常是从输入到输出,目前没有反馈或跳转,因此这些网络也被称为前馈网络。 感知机使用梯度下降算法进行训练。前面章节已经介绍了梯度下降,在这里再深入一点。感知机通过监督学习算法进行学习,也就是给网络提供训练数据集的理想输出。在输出端,定义了一个误差函数或目标函数 J(W),这样当网络完全学习了所有的训练数据后,目标函数将是最小的。 输出层和隐藏层的权重被更新,使得目标函数的梯度减小:
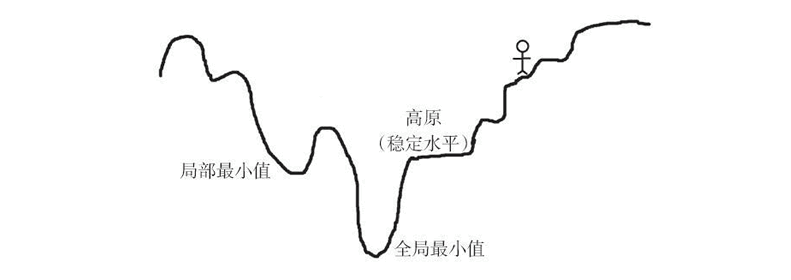
为了更好地理解它,想象一个充满山丘、高原和凹坑的地形。目标是走到地面(目标函数的全局最小值)。如果你站在最上面,必须往下走,那么很明显你将会选择下山,即向负坡度(或负梯度)方向移动。相同的道理,感知机的权重与目标函数梯度的负值成比例地变化。 梯度的值越大,权值的变化越大,反之亦然。现在,这一切都很好,但是当到达高原时,可能会遇到问题,因为梯度是零,所以权重没有变化。当进入一个小坑(局部最小值)时,也会遇到问题,因为尝试移动到任何一边,梯度都会增加,迫使网络停留在坑中。 正如前面所述,针对增加网络的收敛性提出了梯度下降的各种变种使得网络避免陷入局部最小值或高原的问题,比如添加动量、可变学习率。